WebKit
WebKit 作为浏览器内核,结构很复杂,本次主要针对于其几个核心结构进行分析,整体结构不涉及到很细节的代码实现。分析流程包括三步:1. 整体的执行流程,2. 对应源代码中的核心处理类,3. 相关部分细节介绍
HTML 解释器
HTML解释器是对网页中的HTML解析的过程,最后将处理成为DOM树结构。
HTML解释器的输入为网络或者本地磁盘中获取的HTML网页和资源字节流;输出为DOM树结构(WebKit技术内幕 P107)。
这也是浏览器执行的最起始的步骤,当在网页中输入一个URL时,相关字节流数据将会传回给浏览器,HTML解释器将开始处理。
HTML解释器处理流程
字节流处理成为字符流,可以看成就是平时我们看到的网页
1 | <html> |
然后将里面的标签、值等提取出来形成一个个词语token,然后再依据token创建节点,再将其加入到DOM树中完成DOM的构建。
对应于WebKit的处理:
作为框结构的处理,整个作为一个MainFrame,框里面是一个Document,Document里面可以嵌入多个子框,结构类似。

所以处理的入口函数是Frame相关的处理,大致流程如下:
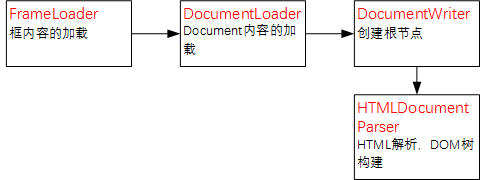
首先是调用FrameLoader,用于框内容的加载,然后在FrameLoader中将加载DocumentLoader用于Document内容的加载;此时将调用DocumentWriter用于创建Document节点,即DOM树的根节点HTMLDocument对象;然后将调用HTMLDocumentParser解析HTML,在根节点的基础上完善DOM树,最终实现DOM树的构建。
对应源代码处理类
加载过程中调用DocumentWriter来创建Document根节点: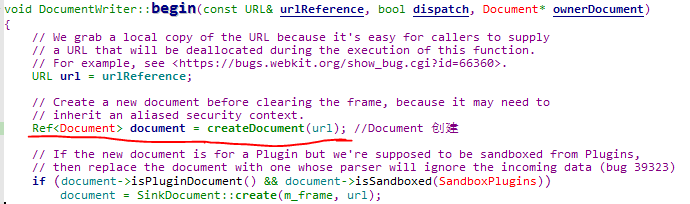
然后将得到一个DocumentParser对象,用于后面的HTML解析
在HTMLDocumentParser中解析HTML代码创建DOM树,主要流程在HTMLDocumentParser::pumpTokenizerLoop函数中,循环处理Token,具体在下图所示: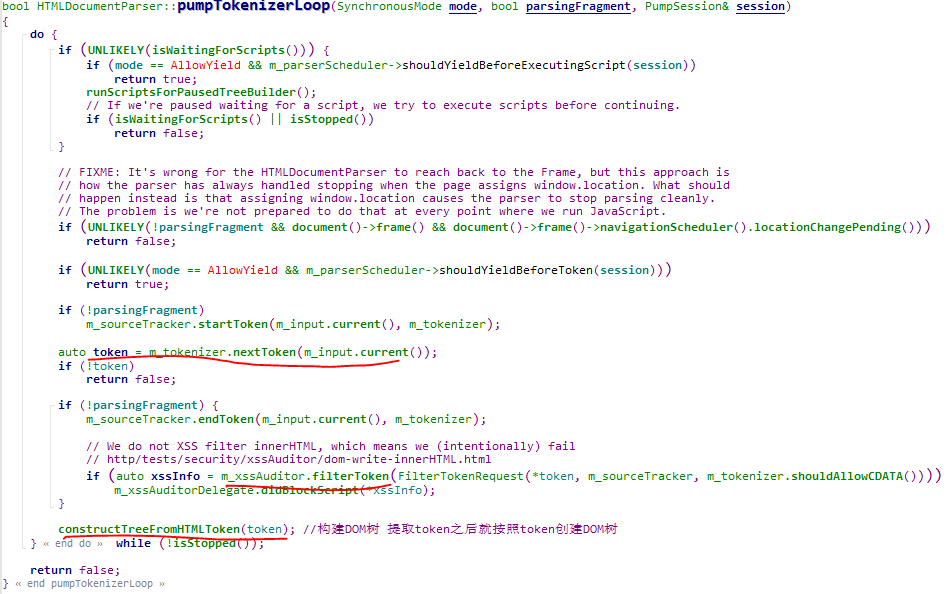
主要包含三步:
- 从HTML字符串中提取出token
- 对提取的token使用XSSAuditor进行过滤
- 依据token进行DOM树的构建
提取token主要由HTMLTokenizer类来进行处理;XSSAuditor过滤用XSSAuditor进行处理,调用filterToken函数;依据token进行DOM树构建主要有HTMLTreeBuilder类来进行处理,调用constructTree函数。
下面重点看一下由token到DOM节点的插入过程。
DOM树的构建
接着上面的描述,当获取到一个token时,将使用其进行DOM构建,即加入到DOM树中,入口函数为HTMLTreeBuilder::constructTree,输入的参数为token。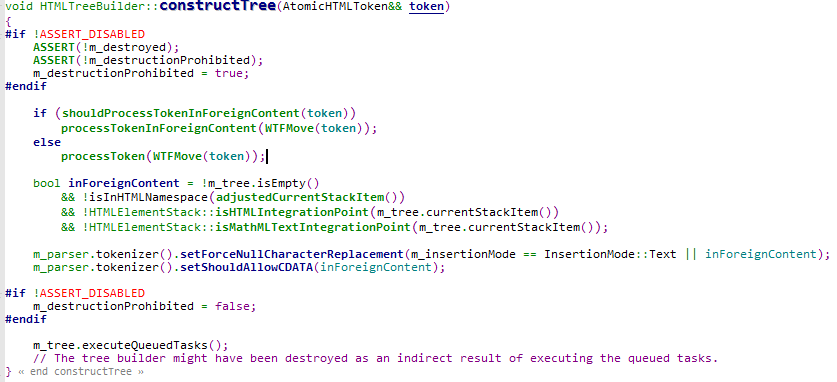
首先是processToken,用于对token的处理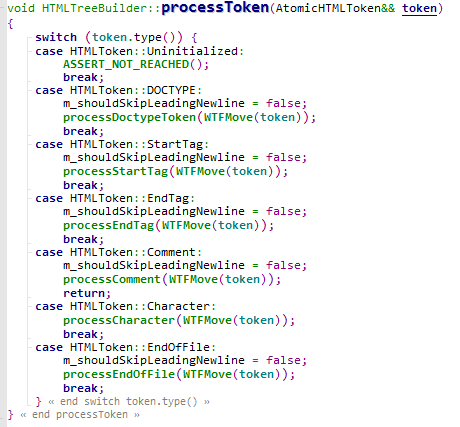
这里会对token进行分类,WebKit对其一共分为了6类,假设这里为StartTag,则进入processStartTag函数进一步处理,然后依据该token需要插入的位置来进一步调用不同的函数处理,例如,判断是否在head之前,然后进一步判断是html标签或是head标签,这里为了简单分析,假设进入的token是一个body标签。
那么将会进入AfterHead分支,然后进一步调用m_tree.insertHTMLBodyElement(WTFMove(token));进一步处理。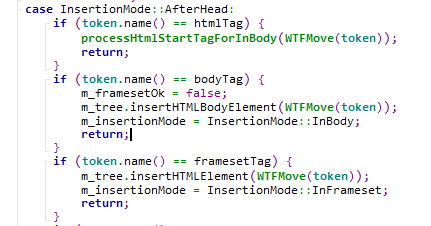
这里m_tree是一个HTMLConstructionSite类的对象,因此将会由HTMLConstructionSite进行节点对象的创建,这里是body将会调用body的创建与插入。在HTMLConstructionSite类中可以发现对很多不同的元素都有相应的函数来进行处理。
这里是对body处理,首先是创建一个body元素对应的对象,然后m_openElements.pushHTMLBodyElement,这里其实是维护了一个元素的栈,m_openElements是HTMLElementStack类的一个对象;这里的元素是当前有开始标识但是还没有结束标识的元素节点。一个比较形象的例子,(WebKit技术内幕 P113)
当HTML包含标签片段:
1 | <body><div><img></img></div></body> |
依次遇到开始标识,然后依次压栈,当”img”处理结束后,遇到”/img”结束标识,然后出栈,img元素就是div元素的子节点;以此类推。
JavaScript 解析引擎
JS引擎包括两个,一个是WebKit默认的JSC(JavaScriptCore),用于Safari里面(未验证);一个是JS V8,用于Chrome里面。这里主要介绍的是默认的JS引擎JSC。
JSC处理的基本流程
基本结构和一般的程序语言编译解释器类似。其流程如下图:
对应JSC的源代码
JSC的源代码在/Source/JavaScriptCore文件夹里
开始在Parser.cpp中,包含的几个关键的变量:m_lexer,用于词法分析器调用,将字符序列转成token序列,在Lexer.cpp中实现
进入解析的入口函数,Parser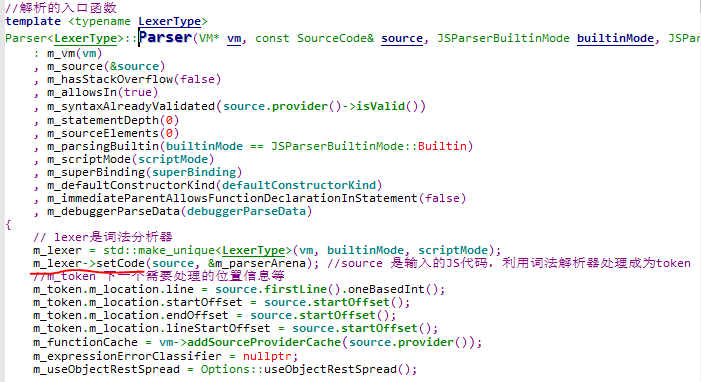
其中source是输入的JS代码,源字符串
参考
WebKit技术内幕
WebKit开源代码(最后修改: 2017-09-03 Sam Weinig)
WebKit vulnerability from 0 to 1 (KCon 2017)